Сегодня я разберу вопрос про сбор семантического ядра на конкретном примере и покажу как создать структуру сайта на основе СЯ. Прежде чем читать данную информацию, необходимо ознакомиться со следующими материалами:
- Что такое семантическое ядро сайта?
- Правильная структура сайта и SEO
Цель: показать как собрать ключевые слова и составить структуру сайта
Сайт: zdorovie-na-kubani.ru . Может быть не самый лучший пример для разбора данного кейса, так как вся семантика для сайта очень большая. Собрать, почистить, а затем еще и структурировать запросы — слишком долго. Поэтому я ограничил количество ключевых слов. Объяснить, что необходимо сделать — несложно. Пару слов о сайте:
- Регион: Краснодар
- Структура уже имеет неплохой вид
Почему именно этот сайт? Я обещал выбрать сайт из предложенных в одном из комментариев. Слово необходимо сдержать:
Программы для работы:
- KeyCollector
- Microsoft Excel
Чуть позже напишу о том, как работаю с каждой программой. KeyCollector — платная программа, но есть бесплатный ограниченный софт — SlovoEB.
ПРОЦЕСС РАБОТЫ
1. Собираем ключевые слова в программе KeyCollector, то есть парсим wordstat Яндекса. Определить список запросов довольно просто — это основные слова, которые приходят первыми на ум. В нашем случае они указаны в горизонтальном меню сайта. Сюда можно добавить еще дополнительные слова: санатории, курорт, доктор, врач и т.п. Данные слова позволяют расширить сайт и всю семантику. Но наша задача в другом — показать как все делать.
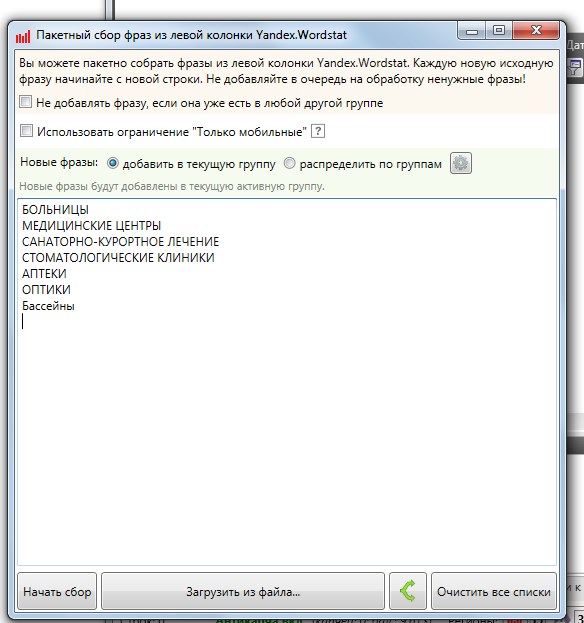
2. Нажимаем кнопку начать сбор и идем заниматься своими делами. В результате получаем список всех ключевых фраз. На картинке лишь маленький фрагмент всего списка:
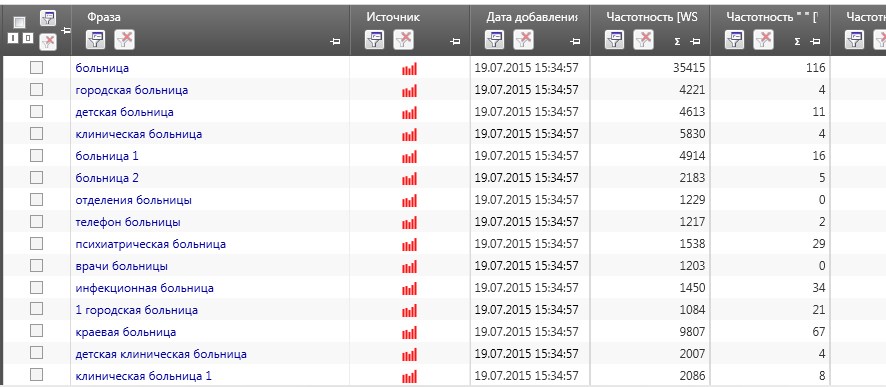
3. Очищаем семантику от мусора. Для этого задаем минус-слова. В нашем случае это может быть: купить, ремонт, своими руками, скачать, видео, смотреть и т.д. Дополнительно необходимо спарсить информацию о количестве запросов (точных и прямых). После чего выгружаем все в Excel:
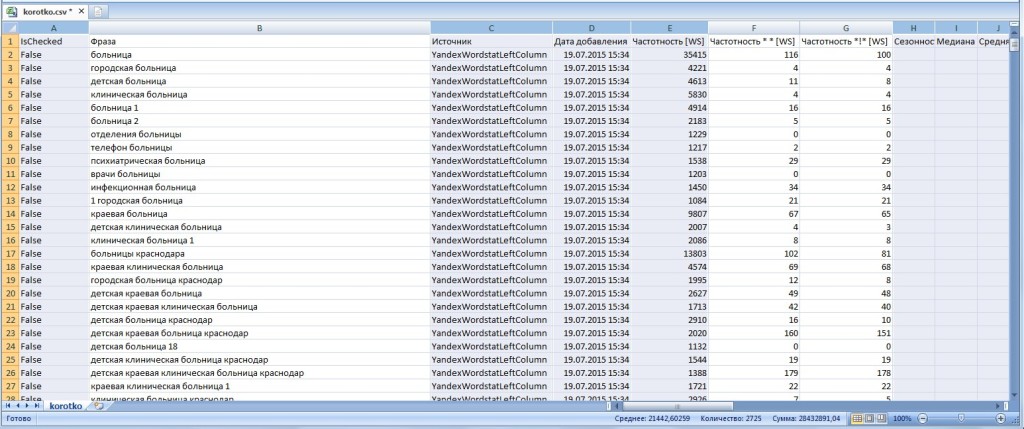
4. Для работы нам нужны только три столбца: B, F и G (фраза, частотность * *[WS], частотность «!»[WS], соответственно). Удаляем ненужные столбцы, слова с нулевыми или неэффективными запросами (по точной частотности). Получаем готовое чистое СЯ. Я парсил только 1-2 страницы и общее количество запросов было чуть больше 1000. Вам необходимо брать информацию и с других страниц в сервисе wordstat.yandex.ru. После чистки у меня вышло 177 запросов. На скриншоте часть семантического ядра после чистки:
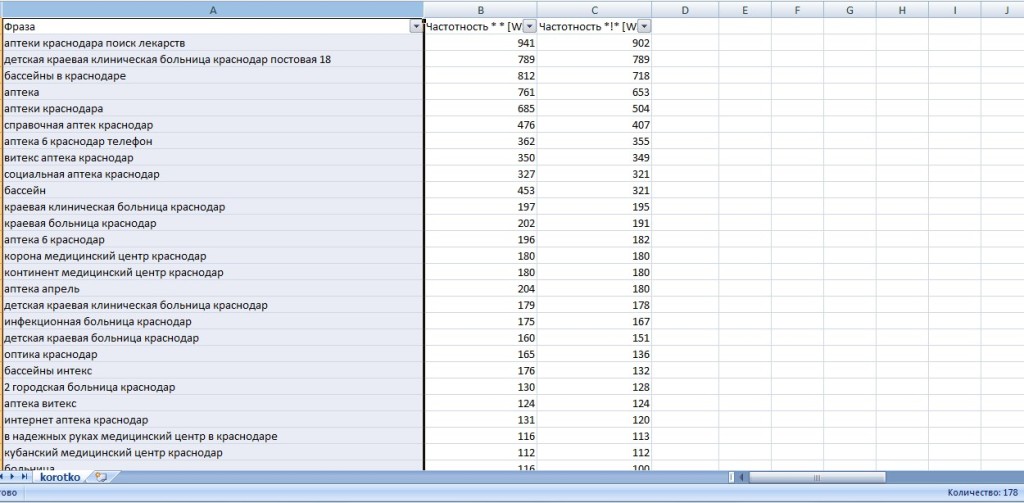
СОЗДАЕМ СТРУКТУРУ САЙТА
1. Теперь необходимо распределить все слова по страницам и создать новую структуру для сайта. Объединяем похожие слова в группы. На 177 запросов вышло 43 группы. В среднем по 4 запроса в группе. На скриншоте ниже часть разбивки:
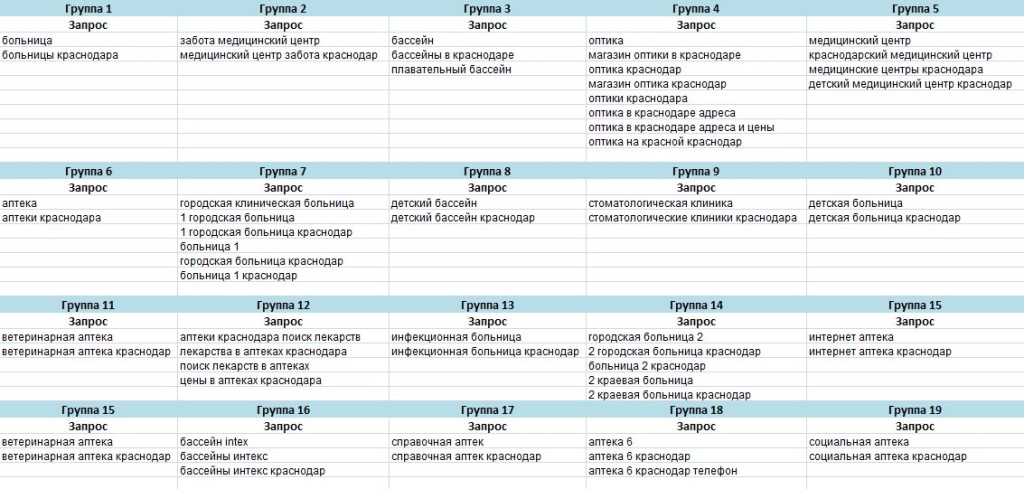
2. Видим из полученной разбивки, что группы можно раскинуть по разделам. Можно сделать следующим образом:
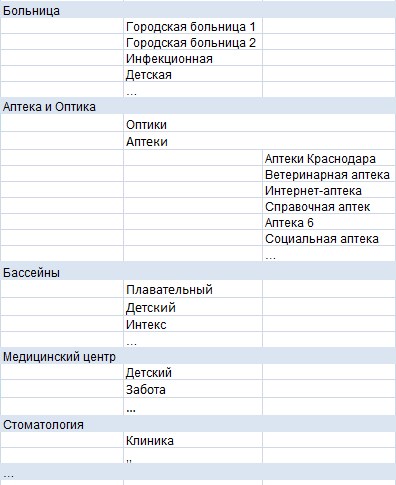
Сразу можно отметить, что все разделы для данного типа сайтов можно предсказать:
- Общие разделы (Больница, Аптека, Оптика и т.д.)
- Раздел+наименование: Аптека 6, Больница 1, Центр Забота и т.п.
- Подраздел: детская, клиническая, городская и т.п.
- Подраздел+наименование: Детская клиническая больница София и т.п.
ПОЛЕЗНЫЙ СОВЕТ
Если для каждого материала на сайте формировать эти поля автоматически и заносить в базу данных сайта, то можно сэкономить кучу времени не только на данном процессе, но и при дальнейшем продвижении.
У данного сайта проблемы с уникальностью контента, как отмечал комментатор. Вопрос можно решить тем, что информация на сайте будет вся по полям с необычной версткой (усложняем, добавляя таблицы и т.д.). Пользователям можно показать адрес заведения не только текстом, но и при помощи динамических карт (например, Яндекс.Карты). Дополнительно предоставить возможность оставлять отзывы о заведении, собрав таким образом уникальный контент на сайте. Для основных разделов будет необходимо написать контент самому.

[…] — соберите все возможные ключевые слова. Например, берем все тот же сайт для медицинского справочника. Подбирая запросы, мы понимаем, что кредиты можно […]